-
[Python]동적 페이지 크롤링(스크래핑) with BeautifulSoup & fake_useragentprogramming/python 2022. 7. 11. 23:33
1.동적 페이지 & 정적 페이지란?
1)정적 페이지 : 서버에 미리 저장된 파일(HTML, IMG, JS)등이 그대로 전달되는 페이지
2)동적 페이지 : 서버에 있는 데이터들을 가공 처리한 후 생성되어 전달되는 페이지를 말합니다.
2.데이터가 동적인지 정적인지 어떻게 알까요?
1)간단하게 말해서 개발자 도구를 열어서 Network 탭에 들어가서 상단에 있는 html 문서에서 찾아보고 없다면 동적 데이터가 되겠습니다.
2)예시
저는 실시간 검색어의 데이터를 얻기 위해서 네이트(www.nate.com)를 예시로 들겠습니다.


검색 결과 1위 - 10위까지 있어야 하는데 1위 - 5위까지만 나와있는 것을 볼 수 있었습니다.
3. 데이터 위치 찾기
데이터를 찾기 위해서는 network 탭에서 찾으시면 되는데, json 파일을 위주로 찾아보시면 보다 쉽게 찾을 수 있을 겁니다.
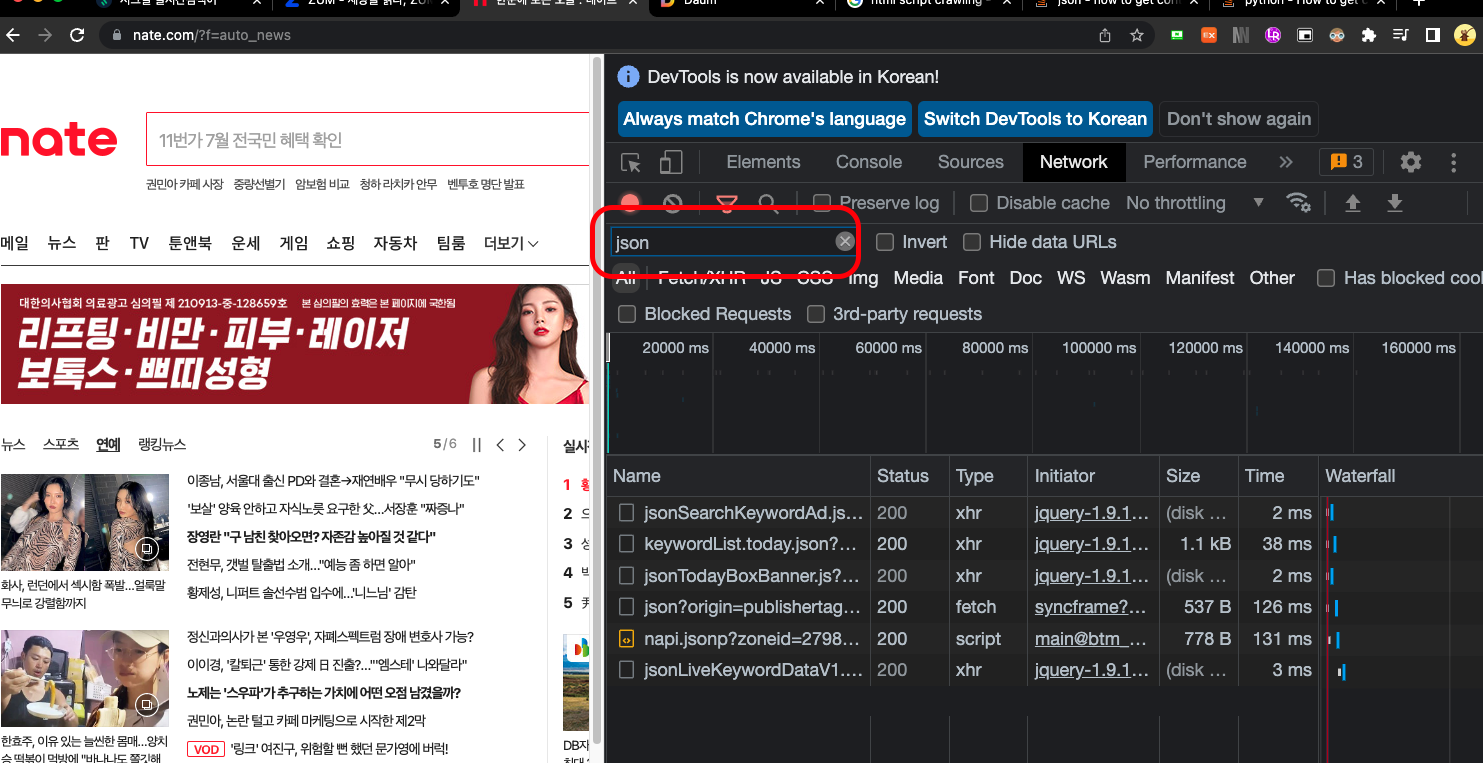

Preview 탭에 들어가면 데이터를 보다 보기 좋게 정리해 주기 때문에 활용을 추천드립니다.
4. 파일의 요청 url 확인 및 referer 확인하기
우리가 찾은 파일을 얻기 위해 어디에 요청해야 하는 찾아야 할 필요가 있습니다.
url은 왜? 그 데이터의 위치(주소)를 알아야 가져올 수 있습니다.
referer이란?
referer은 왜? 본인의 페이지에서 요청한 것이 아니라면 접근이 제어될 것입니다.


5. fake_useragent 설치
pip install fake-useragent
6. 코드 작성하기
import json import urllib.request as req from fake_useragent import UserAgent ua = UserAgent() #시도해 보세요 # print(ua.random) headers = { 'User-agent' : ua.chrome, 'referer': 'https://www.nate.com/' } url = 'https://www.nate.com/js/data/jsonLiveKeywordDataV1.js?' # 요청할url에 우리의 가짜 정보를 header에 넣어 열어주는 것 입니다. res = req.urlopen(req.Request(url, headers=headers)).read().decode("euc-kr") print(res)
7. 입맛에 맞게 데이터 정제하기
제가 가져온 데이터는 리스트 형태로 보이지만 str로 넘어왔습니다. 검색을 통해 list로 만들어 볼 수 있겠지만
연습도 될 겸 만들었습니다.
def str_to_list(arg): li = [] num = 0 source = '' for i in arg: if num == 1: source += i if i == '"': num += 1 if num == 2: li.append(source[:-1]) source = '' num = 0 return li def fiter(x:list): li = [] n = 0 for i in range(len(x)): if i == 5*n+1: li.append(x[i]) n+=1 return li for i in fiter(str_to_list(res)): print(i) print(f'https://new.nate.com/search?q={i}')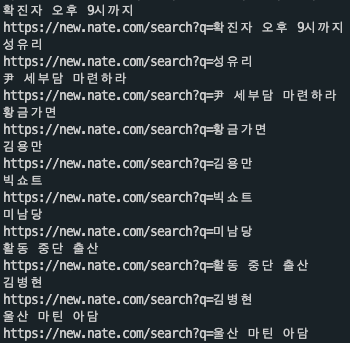
'programming > python' 카테고리의 다른 글
[Flask] 로그인 기능 만들기 ft.JWT,Token,Cookie,hashlib (0) 2022.08.29 [Python] re 모듈을 통해 정규표현식으로 window.__INITIAL_STATE__ 스크래핑[크롤링]하기 (0) 2022.07.15 [Python] getattr 내장 메서드, 함수 이름으로 호출하기 (0) 2022.07.05